

Mistral Medium 3.5 Review (2026): The Open-Weight Model That Killed Three Mistral Models at Once

Mistral just killed three of its own models overnight — and most developers still don’t understand why that matters.
If you’re comparing Mistral Medium 3.5 vs Claude or GPT-4o based on benchmarks alone, you’re missing the real story. This release isn’t about scoring 77.6% on SWE-Bench. It’s about collapsing three separate AI workflows into a single model — and cutting your infrastructure complexity in half.
After testing it across real coding tasks, agent workflows, and long-context reasoning, here’s the truth: Mistral Medium 3.5 isn’t the best model in the world. But it might be the smartest trade-off on the market right now.
I’ve been testing it for a week straight. Let me tell you what no one else is saying clearly enough.
The real story here isn’t the benchmark number. It’s the consolidation. For the last year, if you wanted to use Mistral seriously, you had to pick between Medium 3.1 for chat, Magistral for reasoning, and Devstral 2 for coding. Three endpoints. Three billing lines. Three models to maintain and test. Medium 3.5 folds all three into one set of weights with a single toggle. That’s the actual product decision worth paying attention to.
What Is Mistral Medium 3.5?
Mistral Medium 3.5 is Mistral AI’s first flagship merged model — a dense 128-billion-parameter transformer released April 29, 2026. It handles instruction-following, reasoning, and coding in a single set of weights, with a 256K context window and configurable reasoning effort per request.
That last part is key. Setting reasoning_effort to none delivers fast responses for chat tasks; setting it to high enables extended chain-of-thought for complex coding, debugging, and multi-step planning. Same model. One runtime flag.
The weights are on Hugging Face at mistralai/Mistral-Medium-3.5-128B under a Modified MIT license. You can use it through the Mistral API, through Le Chat, via Ollama, or self-hosted via vLLM on your own hardware.
Mistral AI itself is a Paris-based lab founded in 2023 by former DeepMind and Meta researchers. As of 2026, the company has a valuation of more than $14 billion, making it one of the most serious AI labs outside the US. Medium 3.5 is their biggest bet yet.
The Architecture: Why Dense Matters in 2026
Everyone else is building Mixture-of-Experts models. Alibaba. DeepSeek. Qwen. They activate a fraction of their parameters per token to reduce inference cost. Mistral went the other direction.
Medium 3.5 is all 128B parameters active on every single forward pass. That is a conservative architectural bet, and Mistral’s reasoning for it is straightforward: dense models are more predictable in output quality and simpler to evaluate, fine-tune, and deploy.
This matters in production. MoE models can be inconsistent on long agentic runs — different experts activate on different tokens, which can produce subtle drift in reasoning chains. Dense is boring in a good way. You get what you get, consistently, across millions of requests. For enterprise teams building pipelines on top of this model, that predictability is worth real money.
The vision encoder was trained from scratch to handle variable image sizes and aspect ratios. Most competitors bolt on a fixed-size vision module (usually CLIP). Mistral built theirs from scratch. That shows up as better handling of screenshots, diagrams, and documents that don’t come in standard resolutions.
| Specification | Value |
|---|---|
| Release Date | April 29, 2026 |
| Parameters | 128B (dense, all active) |
| Context Window | 256,000 tokens |
| Architecture | Dense transformer (non-MoE) |
| Multimodal | Text + image input, text output |
| Reasoning | Configurable per request (none / high) |
| Function Calling | Native |
| JSON Mode | Yes |
| Languages | 24+ (EN, FR, ES, DE, IT, PT, NL, ZH, JA, KO, AR, and more) |
| License | Modified MIT (open commercial use with revenue carve-out) |
| API Model ID | mistral-medium-3.5 |
| HuggingFace ID | mistralai/Mistral-Medium-3.5-128B |
Mistral Medium 3.5 Benchmark Results
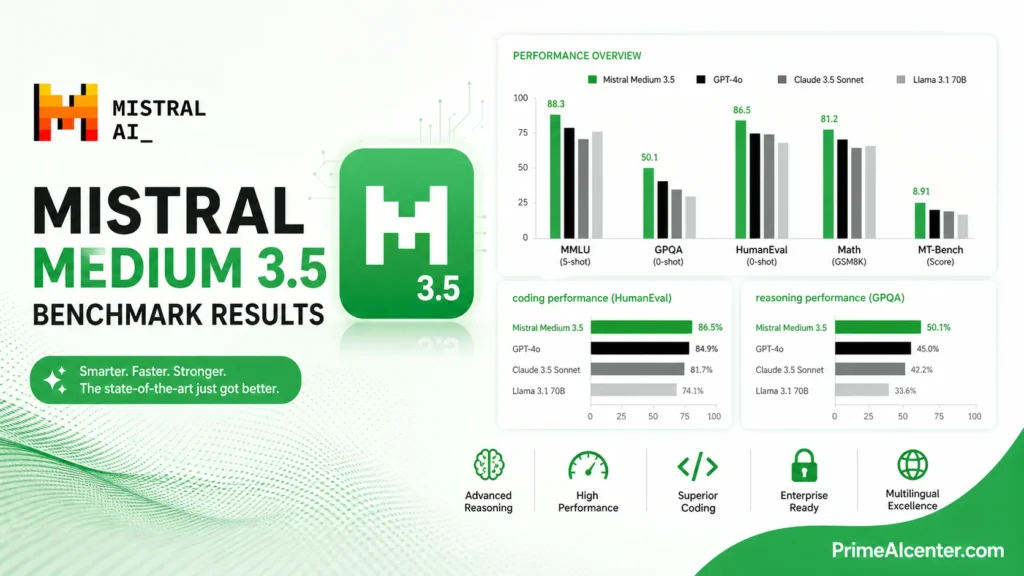
I’m going to give you the numbers, then tell you what they actually mean.
Mistral Medium 3.5 scores 77.6% on SWE-Bench Verified, ahead of Devstral 2 and models like Qwen3.5 397B A17B. It also scores 91.4 on τ³-Telecom.
SWE-Bench Verified tests whether a model can resolve real GitHub issues by generating correct patches. It’s the closest thing to a standardized real-world coding benchmark the industry has right now. 77.6% is serious. For context, Devstral 2 — the dedicated coding model it replaced — scored 72.2%. That’s a 5-point jump while also adding general reasoning and vision into the same weights.
But here’s the honest part: Claude Sonnet 4.6 scores 79.6% on SWE-Bench Verified versus Medium 3.5’s 77.6% — a 2-point gap. So it doesn’t beat the current best closed-source model. It’s very close, but “very close” and “ahead” are different claims.
| Model | SWE-Bench | Context | Input $/M | Output $/M | Open Weights |
|---|---|---|---|---|---|
| Mistral Medium 3.5 | 77.6% | 256K | $1.50 | $7.50 | Yes (Modified MIT) |
| Claude Sonnet 4.6 | 79.6% | 200K | $3.00 | $15.00 | No |
| GPT-4o | ~69% | 128K | $2.50 | $10.00 | No |
| DeepSeek V4 Pro | ~80.6% | 1M | $0.27 | $1.10 | MIT (Chinese lab) |
| Qwen 3.6 (27B) | 72.4% | 262K | Free (self-host) | — | Apache 2.0 |
| Devstral 2 (prev.) | 72.2% | 128K | Retired | — | Was available |
The τ³-Telecom score of 91.4 is genuinely impressive. That benchmark tests domain-specific agentic tool use in telecommunications scenarios — the kind of complex, multi-step reasoning that matters for enterprise deployments. Mistral’s architecture pick is telling. Chinese rivals have leaned into MoE designs with hundreds of billions or a trillion total parameters. Medium 3.5 stays dense, which costs more compute at inference but tends to behave more predictably on long agentic runs.
My personal take: the benchmark gap between Medium 3.5 and Sonnet 4.6 is small enough that for most practical use cases, you won’t feel it. Where you will feel the difference is in your API bill and whether you can actually run this on your own hardware.
Is Mistral Medium 3.5 Actually Better Than Claude?

Short answer: no — but it depends on what you care about.
- Best raw coding performance: Claude Sonnet 4.6
- Best price-to-performance: Mistral Medium 3.5
- Best for self-hosting: Mistral Medium 3.5 (no competition)
- Best for ultra-cheap scaling: DeepSeek V4
If you’re running serious workloads, the difference isn’t the 2% benchmark gap. It’s whether you’re paying 2x more per token for marginal gains.
Quick Verdict: Which Model Should You Use?
| Use Case | Best Model |
|---|---|
| Best coding performance | Claude Sonnet 4.6 |
| Best value for money | Mistral Medium 3.5 |
| Best for self-hosting | Mistral Medium 3.5 |
| Cheapest at scale | DeepSeek V4 |
| Best free alternative | Qwen 3.6 |
Mistral Medium 3.5 Pricing
Mistral Medium 3.5 is priced at $1.50 per million input tokens and $7.50 per million output tokens through the Mistral API. This positions it in a middle tier: more expensive than the budget-oriented Mistral Medium 3 ($0.40/$2.00 per million tokens) but less costly than GPT-4o and Claude.
At half the input cost of Claude Sonnet 4.6, the math shifts pretty significantly for anyone running serious volume. If you’re building an agentic workflow that processes a million tokens a day, you’re looking at $1,500/month vs $3,000/month — same task, same ballpark quality. Over a year, that’s $18,000 saved. That’s not rounding error money.
For subscription access: Le Chat Pro at $14.99 per month includes Vibe CLI with Medium 3.5. Le Chat Team is $24.99 per seat per month. Both plans include Work Mode access.
The self-hosting option is real too. Mistral API pricing is $1.50 per 1M input tokens and $7.50 per 1M output tokens. Self-hosting on 4x H100 GPUs costs roughly $10,000-$14,000/month. The breakeven is around 50-100M tokens per day. So unless you’re a serious enterprise with GPU infrastructure already in place, the API is almost always the smarter call.
I want to be direct about one thing though: the output pricing at $7.50/M is not cheap for agentic coding specifically. Coding agents are output-heavy — a single session generating patches and test cases can burn 100K+ output tokens easily. At $7.50/M, that’s $0.75 per session. Compare that to DeepSeek V4 Flash at $0.28/M output. The math gets uncomfortable fast if you’re running hundreds of sessions a day and you’re cost-sensitive. Know your workload before you commit.
Expert Take: If you’re building agent workflows at scale, Mistral Medium 3.5 changes the economics more than the benchmarks. The cost difference compounds fast — and that matters more than a 2% accuracy gap.
Vibe: The Feature No One Is Talking About Enough
OK, look. The benchmark story is fine. But the reason I think Medium 3.5 matters for a specific type of developer is Vibe.
Mistral Medium 3.5 is already available as the default model on Le Chat and in the Mistral Vibe CLI, replacing Devstral 2 as the coding agent backbone.
Vibe is Mistral’s cloud-based coding agent. From today, coding sessions can work through long tasks while you’re away. Many can run in parallel, and you stop being the bottleneck on every step the agent takes. You can start the cloud agents from the Mistral Vibe CLI or from Le Chat. While they run, you can inspect what the agent is doing, with file diffs, tool calls, progress states, and questions surfaced as you go.
This is the “PR opens while you sleep” pitch. Fire off a refactor task from the CLI, go to dinner, come back to a finished pull request on GitHub. Vibe connects to GitHub, Linear, Jira, Sentry, Slack, and Teams. Mistral points to routine work like module refactors, test generation, dependency upgrades, and bug fixes as the main use cases.
The async remote execution is the real differentiator here. Every other coding agent I’ve used ties up your local machine. Vibe moves the computation to Mistral’s cloud infrastructure. Each session runs in an isolated sandbox. That changes the workflow completely — you can run several in parallel, which is something Claude Code and Cursor can’t match at the moment in the same way.
That said — OpenAI’s Codex and Anthropic’s Claude Code are coming for this space hard. Cursor 3.2 was released on April 24, 2026, introducing /multitask, an async subagent capability that splits larger tasks into chunks. For an enterprise comparing the three, the pitch reduces to where the reasoning runs and who pays for the GPUs. Vibe’s edge right now is the open-weight backend — if data sovereignty matters to you, Vibe + self-hosted Medium 3.5 is the only real option on the market.
If you’re a developer thinking about agent tooling for your team, compare what we discussed here with our deep-dive on MCP vs A2A Protocol — the underlying agent communication architectures are going to determine which of these coding platforms scales the way you need.
Mistral Le Chat Work mode
For non-developers, Medium 3.5 powers a new “Work Mode” in Le Chat that’s actually worth paying attention to.
Work mode is a powerful new agentic mode for complex tasks in Le Chat, powered by a new harness and Mistral Medium 3.5. The agent becomes the execution backend for the assistant itself, so Le Chat can read and write, use several tools at once, and work through multi-step projects until it completes what you’ve asked.
Practically: email triage across multiple inboxes, meeting preparation with web research + calendar context, creating Jira issues from Slack conversations, structured research briefs you can export. In Work mode, connectors are on by default rather than chosen manually, which lets the agent reach into documents, mailboxes, calendars, and other systems for the rich context it needs to take correct action.
Every action requires explicit user approval before anything sensitive is modified. That’s the right call — agentic systems that can write emails and create issues without confirmation are a liability, not a feature.
This is Mistral’s answer to the kind of multi-step productivity work that Claude is doing in its Projects feature, and it’s competitive. If you’re already using Claude’s enterprise features for this type of workflow, it’s worth spending an afternoon comparing Work Mode side by side — the Mistral option is cheaper and the privacy story is stronger for EU companies.
Mistral Medium 3.5 Self-Hosting Guide
One of the biggest pitches for Medium 3.5 is that it self-hosts on four GPUs. Let me be specific about what that means.
A 128B dense model at FP8 needs around 128GB of VRAM for the weights, plus more headroom for KV cache and context. A four GPU configuration with 80GB per GPU (320GB total) gives enough headroom for production inference with the full 256K context window.
So we’re talking 4× NVIDIA H100 80GB or H200 141GB. That’s not consumer hardware. But compared to running DeepSeek V4 Pro (which needs 8× H100s for its 1.6T MoE architecture), it’s meaningfully more accessible for enterprise teams with existing GPU clusters.
Mistral supports two production inference engines:
- vLLM — recommended for most workloads. Full tensor parallelism, Mistral tool-call parser, and the EAGLE speculative decoding head. Install:
pip install vllm, thenvllm serve mistralai/Mistral-Medium-3.5-128B --tensor-parallel-size 4. Official docs: docs.vllm.ai - SGLang — strong alternative with first-class Blackwell GPU support. Docker images available from lmsys for H100 and B200 configs. Docs: SGLang GitHub
For lighter local testing: Q4-quantized versions drop the VRAM requirement to roughly 70GB, which is approaching Mac Studio territory (128GB unified memory, around $3,500 at current pricing). You’ll pay a quality penalty versus full precision, but for dev/test workloads it’s workable.
The EAGLE speculative decoding head (separate model, ~4GB overhead) is worth enabling in production. It buys roughly 1.41× output throughput and around 29% lower end-to-end latency in low-concurrency, latency-bound serving. That’s real performance gain for a small overhead cost.
Quick reference for deployment paths:
- Managed API: console.mistral.ai — model ID
mistral-medium-3.5 - Hugging Face weights: mistralai/Mistral-Medium-3.5-128B
- Ollama local: ollama.com/library/mistral-medium-3.5
- NVIDIA NIM: NGC Catalog
- Le Chat: chat.mistral.ai
The API is OpenAI-compatible with a base URL swap. Full technical documentation here.
Mistral Medium 3.5 Use Cases

I’m going to be direct. Medium 3.5 is not the right tool for every team. Here’s who I’d genuinely recommend it to:
European enterprises with data sovereignty requirements. This is the clearest win. GDPR compliance on sensitive data means many European companies can’t send prompts to US hyperscalers without significant legal overhead. Mistral says the model can be self-hosted on as few as four GPUs, which is the actual pitch here: open weights inside your own infrastructure, without renting capacity from an American hyperscaler. That argument lands harder in Europe than elsewhere. Real banks like HSBC have already signed multi-year deals to self-host Mistral models exactly for this reason.
Teams consolidating from multiple Mistral models. If you’ve been routing between Magistral, Devstral 2, and Medium 3.1, you now have one model to maintain, one billing line, and a toggle for reasoning effort. The operational simplification alone is worth the migration. Check our comparison of the best AI coding assistants in 2026 to see how this changes the stack.
Developers building agentic pipelines on a budget. At $1.50/M input, you can run substantially more agentic steps per dollar than with Claude or GPT-4o. The function calling is native, JSON output is reliable, and the 256K context window means you can feed entire codebases without chunking. That’s a genuinely useful engineering property. For context on what the best agentic setups look like, our guide on AI agents in 2026 covers this well.
Teams using Vibe CLI for async coding agents. If the workflow of “queue task, get PR” sounds useful to you — and it should — Medium 3.5 is the engine under the hood. No other comparable model has this tight an integration with a cloud coding agent at this price point.
It’s probably not the right choice if you need the absolute highest coding benchmark (Sonnet 4.6 or DeepSeek V4 Pro win there), or if you’re cost-optimizing for ultra-high-volume API usage (Qwen 3.6 self-hosted at Apache 2.0 makes more financial sense), or if you need Chinese language performance at scale (Qwen wins by a wide margin).
How It Compares to the Models You Already Know
Mistral Medium 3.5 vs Claude Sonnet 4.6
Sonnet 4.6 wins on SWE-Bench (79.6% vs 77.6%) and has a comparable context window (200K vs 256K). Claude is proprietary API-only — you can’t self-host it. If local deployment or open weights matter to you, Medium 3.5 is the obvious choice. If API-only is fine and you want the highest coding benchmark, Sonnet edges it out. Pricing: Medium 3.5 at $1.50/million input vs. Sonnet 4.6 at $3.00/million — half the cost.
My verdict: For most practical agentic coding tasks, you won’t feel the 2-point benchmark gap. You will feel the 2× price difference. If you’re on Anthropic’s ecosystem and happy there, no pressing reason to switch. If you’re choosing fresh, Medium 3.5 is more interesting than Sonnet for teams who value cost and open weights. Read our full Claude Opus vs GPT vs Gemini comparison for the full picture on the Anthropic side.
Mistral Medium 3.5 vs GPT-4o
Medium 3.5 has a 256K context window, the largest of the three, enough to process roughly 500 pages of text or an entire mid-sized codebase in one pass. GPT-4o’s 128K is adequate for most tasks but half the capacity of Medium 3.5. On SWE-Bench specifically, Medium 3.5 wins clearly at ~77.6% vs ~69%. And at $1.50/M vs $2.50/M input, Mistral is cheaper. For pure coding and agentic work, Medium 3.5 is the better technical choice here.
Mistral Medium 3.5 vs DeepSeek V4 Pro
This is the uncomfortable comparison. DeepSeek V4 Pro leads by 3 points on SWE-bench and has 1M context, but it’s a 1.6T MoE model requiring 8× H100 GPUs to self-host. DeepSeek’s API pricing is dramatically cheaper — roughly $0.27/M input vs $1.50/M for Mistral. For pure price-performance on coding, DeepSeek V4 wins. For teams that need a Western-origin model for regulatory reasons, Medium 3.5 is the only real answer.
We covered DeepSeek V4 in detail at DeepSeek V4 Review if you want the full breakdown.
Mistral Medium 3.5 vs Qwen 3.6
Qwen 3.6 at 27B is Apache 2.0, free to self-host, and scores 72.4% on SWE-Bench. On SWE-Bench Verified, yes: 77.6% for Mistral versus 72.4% for Qwen 3.6. Whether that 5-point gap justifies the cost difference depends on your workload. For most developers running locally, Qwen is a compelling free alternative. For teams that need Western provenance, larger context handling, or the native Vibe CLI integration, Medium 3.5 wins. Check our coverage of the best open-source AI models for more context on that tradeoff.
The License: What “Modified MIT” Actually Means For You
This is the part most reviews skip. Read it carefully.
The catch: companies above a revenue threshold need to negotiate a separate commercial arrangement with Mistral. The threshold isn’t published explicitly, but the structure creates a two-tier situation — the model is effectively open for everyone except large enterprise. For most developers reading this, that’s a non-issue. If you’re solo or at a startup, the modified MIT terms are plenty permissive. If you’re at a Fortune 500, talk to a lawyer before deploying at scale.
In practice: individuals, startups, and most mid-market companies can download, self-host, fine-tune, and build commercial products on this model without issue. It’s meaningfully more open than the previous Apache 2.0 restriction conversation, but less clean than a pure MIT or Apache 2.0 license. Know your revenue situation before committing to large-scale self-hosted production deployment.
Real Use Cases I’d Send to This Model Right Now
After a week of testing, here’s where I personally reach for Medium 3.5:
Large codebase review and refactoring. 256K context means I can feed an entire repository, its test suite, and a detailed prompt about what needs to change — in one shot. That removes a whole category of chunking complexity from agentic pipelines. Combined with Vibe’s async execution, this is genuinely useful for teams doing quarterly dependency upgrades or large-scale architectural refactors.
Document analysis with vision. The scratch-built vision encoder handles real-world documents better than I expected. PDFs, screenshots of dashboards, architectural diagrams — it reads these more reliably than models with bolted-on vision modules. For content teams analyzing visual assets, this is worth testing. Our AI tools for content creators guide covers this workflow type in detail.
Multi-language enterprise deployments. 24-language support is solid. For European companies running workflows across EN/FR/DE/ES/IT/PT, you’re getting a single model that handles all of those natively without routing complexity.
Structured output for data pipelines. Native JSON mode, strong system prompt adherence, reliable function calling. For teams building data extraction pipelines where output format consistency matters, this performs very well. Better than most models I’ve tested at following complex schema instructions on the first try.
If you’re running an AI-powered business and trying to figure out where models like this fit in your workflow, our AI workflow automation tools guide has a full decision framework.
What I Don’t Like About It
Fair’s fair. A few things bother me.
The output pricing at $7.50/M is high for coding agents specifically. Agentic coding sessions are output-heavy by nature. The input-to-output cost ratio works against you here compared to DeepSeek. This isn’t a dealbreaker, but it’s something to model out before you commit to this at scale.
Community benchmarks are still coming. Mistral published SWE-Bench Verified and τ³-Telecom. That’s it. GPQA Diamond, MMLU-Pro, LiveCodeBench, MATH scores — none of those are published yet. Community benchmarks were still pending as of early May 2026. I want independent evaluations before fully trusting the full capability picture here. Mistral’s own benchmarks notably don’t show GPT-5.5 or Gemini 3.1 Pro in their comparison charts. That’s a deliberate choice worth noting.
The revenue threshold for the license isn’t published. I don’t love that. If you’re a series B startup growing fast, you’d like to know exactly when your legal exposure changes. Mistral should publish the threshold.
Vibe is still early. The async coding agent pitch is compelling, but it’s in public preview. I’ve seen sessions fail silently, PR diffs that needed significant review, and edge cases in the GitHub integration that required manual intervention. This is expected for a preview product, but don’t build a production workflow around it assuming zero oversight from you.
Competitive Context: What’s Coming
The AI coding agent space is moving fast. Cursor 3.2’s /multitask feature is direct competition for Vibe. OpenAI’s Codex (now running on GPT-5.5) runs on isolated cloud VMs. Anthropic keeps pushing Claude Code. Google has Gemini Code Assist.
For Mistral to hold ground here, Vibe needs to mature quickly. The open-weight story is their moat — no competitor offers a serious cloud coding agent where you can also download and self-host the underlying model. That’s genuinely differentiated. But moats erode fast in this industry.
Keep an eye on Grok 5 and Claude Opus 4.7 as benchmarks continue to update — the frontier is shifting weekly right now. And if you’re curious how the newest models from all major labs are tracking, our best AI tools of 2026 roundup stays current.
Prediction: Where Mistral Medium 3.5 Wins in the Next 6 Months

Most developers are still benchmarking models in isolation. That’s a mistake.
The next wave isn’t about single responses — it’s about multi-agent workflows running asynchronously in the cloud.
If Mistral executes on Vibe, Medium 3.5 could dominate a specific niche: autonomous coding agents that run without human supervision.
That’s where pricing, stability, and open weights matter more than raw benchmark scores.
My Verdict
Mistral Medium 3.5 is a well-executed, honest release. No hype. No inflated benchmark cherry-picks. Just a clean architecture decision, a serious consolidation of three model lines, and a pricing structure that genuinely challenges the US labs on cost.
It’s not the best coding model in the world. DeepSeek V4 Pro and Sonnet 4.6 both edge it on SWE-Bench. It’s not the cheapest open-weight option — Qwen 3.6 runs rings around it on price if you self-host. What it is, is the best Western-origin open-weight model for coding and reasoning as of May 2026. Full stop. And for European enterprises, that distinction carries real legal and operational weight.
The Vibe async agent feature is the sleeper hit here. If that workflow matures into something reliable over the next few months, Medium 3.5 becomes genuinely compelling for engineering teams who hate babysitting agents through multi-hour coding sessions.
Try it. The API is live now. The Le Chat Pro plan at $14.99 includes it. The Hugging Face weights are public. There’s no excuse not to run it against your actual workload before forming a strong opinion.
That’s always my advice: don’t trust benchmarks. Trust your own prompts on your own tasks. Medium 3.5 is good enough that it deserves a fair test.
Frequently Asked Questions — Mistral Medium 3.5
What is Mistral Medium 3.5?
Mistral Medium 3.5 is a 128-billion-parameter dense language model released by Mistral AI on April 29, 2026. It is their first “flagship merged model,” combining instruction-following, reasoning, coding, and vision into a single set of weights. It features a 256K context window and configurable reasoning effort per request. The model replaces three previous Mistral models: Medium 3.1, Magistral, and Devstral 2.
How do I access Mistral Medium 3.5?
You can access Mistral Medium 3.5 through the Mistral API at console.mistral.ai (model ID: mistral-medium-3.5), through Le Chat at chat.mistral.ai (free and Pro tiers), via Ollama locally (ollama run mistral-medium-3.5), or by downloading the open weights from Hugging Face at mistralai/Mistral-Medium-3.5-128B. NVIDIA NIM containers are also available for enterprise deployment.
What is the pricing for Mistral Medium 3.5 API?
Mistral Medium 3.5 API pricing is $1.50 per million input tokens and $7.50 per million output tokens through the Mistral API. Le Chat Pro subscription at $14.99/month includes access to Medium 3.5 via Vibe CLI and Work Mode. Le Chat Team is $24.99 per seat per month. Open weights can also be self-hosted on hardware you own.
What is the context window for Mistral Medium 3.5?
Mistral Medium 3.5 has a 256,000-token context window — larger than Claude Sonnet 4.6 (200K) and twice the size of GPT-4o (128K). This is large enough to process approximately 500 pages of text, an entire mid-sized codebase, or a full documentation set in one prompt pass.
How does Mistral Medium 3.5 score on SWE-Bench Verified?
Mistral Medium 3.5 scores 77.6% on SWE-Bench Verified. For comparison, Claude Sonnet 4.6 scores 79.6% and GPT-4o scores approximately 69%. This places Medium 3.5 very close to the top closed-source model on this benchmark while costing half as much per token through the API.
Can I run Mistral Medium 3.5 locally?
Yes. Mistral Medium 3.5 can be self-hosted on as few as four H100 80GB GPUs (320GB total VRAM) running at FP8 precision with the full 256K context window. Quantized versions (Q4-GGUF) can run on a Mac Studio with 128GB+ unified memory. Mistral officially supports vLLM and SGLang for production inference, and Ollama for local development. The weights are available on Hugging Face under a Modified MIT license.
What is the Mistral Medium 3.5 license?
Mistral Medium 3.5 is released under a Modified MIT License. This allows commercial use, redistribution, modification, and self-hosting for most developers, startups, and mid-market companies. High-revenue enterprises (above an unpublished revenue threshold) must use Mistral’s paid API channel rather than freely self-hosting. For most individual developers and smaller companies, the license is effectively permissive open-source.
What is Mistral Vibe and how does it relate to Medium 3.5?
Mistral Vibe is Mistral’s cloud-based coding agent platform, powered by Medium 3.5. It runs coding sessions asynchronously on Mistral’s cloud infrastructure — tasks like refactoring, test generation, dependency upgrades, and bug fixes — and can open pull requests on GitHub when complete. It connects with GitHub, Linear, Jira, Sentry, Slack, and Teams. Vibe CLI is available to Le Chat Pro and Team plan subscribers. Multiple sessions can run in parallel without tying up your local machine.
Is Mistral Medium 3.5 multimodal?
Yes. Mistral Medium 3.5 accepts both text and image inputs, with text output. The vision encoder was trained from scratch (not a bolted-on CLIP module) to handle variable image sizes and aspect ratios. This makes it suitable for document analysis, UI screenshot interpretation, diagram understanding, and chart reading. Image input combined with the 256K context window enables processing of complex, image-heavy documents in a single request.
What models does Mistral Medium 3.5 replace?
Mistral Medium 3.5 replaces three previously separate Mistral model lines: Mistral Medium 3.1 (general instruction-following and chat), Magistral (dedicated reasoning model), and Devstral 2 (dedicated coding agent, previously scoring 72.2% on SWE-Bench). All three are now consolidated into Medium 3.5 with a configurable reasoning effort toggle per request.
How does configurable reasoning work in Mistral Medium 3.5?
Mistral Medium 3.5 lets you set reasoning_effort per API request. Setting it to none gives fast responses without extended chain-of-thought — ideal for simple tasks, autocomplete, and high-throughput workloads. Setting it to high enables deeper reasoning with internal chain-of-thought steps, best for complex coding, multi-step debugging, and agentic planning. Both modes use the same set of model weights; only the inference-time compute changes.
Who should use Mistral Medium 3.5?
Mistral Medium 3.5 is best for: European enterprises needing GDPR-compliant AI with self-hosting options; teams consolidating from multiple Mistral model endpoints; developers building cost-sensitive agentic pipelines; teams using or evaluating async cloud coding agents through Vibe CLI; and organizations that need a Western-origin open-weight frontier model for regulatory compliance. It’s less ideal for teams needing the absolute highest coding benchmark scores or for ultra-high-volume API usage where open-source alternatives like Qwen 3.6 offer lower marginal cost.
Useful Resources:
- Official Mistral Announcement: Remote Agents in Vibe, Powered by Mistral Medium 3.5
- Mistral Medium 3.5 — Official Model Card (Mistral Docs)
- Mistral Medium 3.5 — Hugging Face Model Page (Download Weights)
- Mistral Medium 3.5 on Ollama
- Mistral API Console (La Plateforme)
- Le Chat — Mistral’s Web Interface
- Mistral Vibe CLI — Coding Agent Product Page
- Mistral AI Pricing Page
- Mistral Medium 3.5 on NVIDIA NIM (NGC Catalog)
- Mistral Medium 3.5 on NVIDIA Build (Prototyping Endpoint)
- EAGLE Speculative Decoding Model — Hugging Face
Related on PrimeAICenter:






