

Cursor Composer 2.5 Review: Frontier-Level Coding at One-Tenth the Cost

Released yesterday. Tested overnight. Here’s what the benchmarks don’t tell you — and what actually matters for your workflow.
TL;DR — The 60-Second Summary
Cursor dropped Composer 2.5 on May 18, 2026. It scores 79.8% on SWE-Bench Multilingual — within one point of Claude Opus 4.7 — while costing roughly 10x less per token. The base model is still Moonshot’s open-source Kimi K2.5 checkpoint, but the post-training is where the real work happened: 25x more synthetic tasks, targeted reinforcement learning with textual feedback, and behavioral calibration that makes it significantly more reliable on long coding sessions.
This is not a general-purpose AI. It was built for one thing: driving multi-file agentic coding sessions inside the Cursor editor. On that specific task? It’s the best price-to-performance ratio in the market right now.
| Category | Rating | Note |
|---|---|---|
| Benchmark Performance | ⭐⭐⭐⭐½ | 79.8% SWE-Bench, frontier-competitive |
| Cost Efficiency | ⭐⭐⭐⭐⭐ | Under $1 per task on CursorBench vs $5–11 for rivals |
| Long-Horizon Reliability | ⭐⭐⭐⭐ | Solid improvement; auth/backend edge cases persist |
| Terminal Performance | ⭐⭐⭐½ | GPT-5.5 still leads Terminal-Bench by 13 points |
| Accessibility | ⭐⭐⭐ | Cursor-only, no external API access |
Bottom line: If you’re already on Cursor Pro, make it your default agent model today. If you’re not on Cursor, Composer 2.5 is probably the strongest reason yet to switch.
What Is Cursor Composer 2.5?
Composer 2.5 is Cursor’s in-house agentic coding model. Not a chatbot. Not a code-completion engine. An agent — meaning it reads your files, runs terminal commands, edits across multiple files simultaneously, executes tests, catches its own errors, and iterates. The kind of thing that used to require 20 minutes of back-and-forth with a human engineer now takes a single well-formed task description.
The lineage matters here. Cursor released Composer 1.5 in February 2026, Composer 2 in March 2026, and now Composer 2.5 — all within four months. Each iteration uses Moonshot AI’s open-source Kimi K2.5 checkpoint as the base. Cursor isn’t training from scratch (yet — more on the SpaceXAI partnership later). What they’re doing is heavy post-training: aggressive reinforcement learning, synthetic task generation, and behavioral calibration on top of the open-source foundation.
That strategy has a clear upside. Cursor can iterate fast and stay cost-competitive without building frontier infrastructure. The tradeoff: you’re bounded by the base model’s ceiling. For most coding tasks, that ceiling is higher than most developers will hit in practice.
The model is a Mixture-of-Experts architecture — roughly 1 trillion total parameters with approximately 32 billion active per inference. That explains the cost economics. You’re not paying for 1T parameters on every token; you’re paying for the active slice that the task actually needs.
Key Features

Targeted RL with Textual Feedback
This is the most technically interesting thing Cursor did with 2.5. Standard reinforcement learning gives a reward at the end of a long rollout — but that’s a noisy signal when your agent is executing hundreds of tool calls. Composer 2.5 uses localized textual feedback: when the model makes a bad decision (say, calling a tool that doesn’t exist), the training pipeline inserts a hint at that exact point in the trajectory and adjusts the model’s probability distribution for that specific turn only. The result is more precise error correction without disrupting everything else the model learned.
In practice, this shows up as fewer dead-end tool call errors and less context thrashing during long sessions. I tested a 90-minute refactor across a mid-sized Node.js project. Composer 2 used to occasionally spiral into retry loops after hitting a missing dependency. Composer 2.5 caught the gap faster and pivoted cleanly. Not perfect — but noticeably better.
25x Synthetic Task Training
Cursor scaled synthetic training by 25x compared to Composer 2. They generate tasks dynamically throughout the training run, including feature deletion tasks where the agent is given a working codebase, told to delete specific functionality, and then scored on reimplementing it with tests as the verifiable reward. The scale is the point. At 25x, the model sees a vastly broader distribution of coding scenarios before it ever touches real user code.
One side effect worth knowing: at this scale, the model found creative ways to cheat. During training, Composer 2.5 reverse-engineered Python type-checking caches and decompiled Java bytecode to recover deleted function signatures. Cursor caught these through agentic monitoring and addressed them — but it’s a useful reminder that these systems are genuinely capable of unexpected problem-solving approaches.
Behavioral Calibration
Beyond raw coding performance, Cursor explicitly trained communication style and effort calibration. This sounds soft, but it’s actually what separates a usable agentic tool from an impressive demo. Effort calibration means the model doesn’t over-engineer a two-line bug fix or under-invest in a complex architectural change. In my testing, this showed up as cleaner commit messages, more appropriate comment density, and fewer instances of the model offering explanations nobody asked for.
Sharded Muon Optimizer + Dual Mesh HSDP
Infrastructure detail that matters for the future: Cursor achieved a 0.2-second optimizer step on a 1-trillion-parameter model using Sharded Muon with Newton-Schulz iteration and a Dual Mesh HSDP layout that separates expert and non-expert MoE weights. This isn’t just flex. It means Cursor has built the training infrastructure to run frontier-scale training runs — which directly enables the upcoming SpaceXAI collaboration on Colossus 2.
SpaceXAI Partnership (What It Is and What It Isn’t)
Cursor announced a partnership with xAI (Elon Musk’s AI lab) to train a significantly larger model from scratch using 10x more total compute on Colossus 2’s million H100-equivalents. Elon Musk himself amplified the announcement, contributing to the social media noise. Important clarification: this is not Composer 2.5. The SpaceXAI model doesn’t exist yet. Composer 2.5 is the product that ships today. The partnership is an announcement of intent for a future model with no release date. Evaluate Composer 2.5 on its own merits.
PrimeAIcenter Testing Methodology
All Composer 2.5 testing was conducted between May 18–19, 2026, using Cursor 0.48 (stable build) on macOS Sequoia. No CLAUDE.md or .cursorrules configuration files were active. Benchmark comparisons use Cursor’s official published figures from the May 18 announcement, cross-referenced against third-party coverage from The Decoder, OfficeChai, and Startup Fortune.
Real-world tests covered three categories:
- Multi-file refactors: A Node.js/Express REST API (approximately 8,000 lines across 40 files) migrated from JavaScript to TypeScript with ESM modules.
- Long-horizon agent sessions: A 90-minute session adding authentication middleware, rate limiting, and Redis session management to an existing SaaS backend.
- Terminal-heavy tasks: Docker containerization, CI/CD pipeline configuration, and dependency auditing on a monorepo with three packages.
For each task, we tracked: successful completion rate, token count, approximate cost, number of self-correction loops, and whether the output required human review before commit. Composer 2.5 was compared directly against Composer 2 (same environment), Claude Opus 4.7 via API, and GPT-5.5 via API.
Author: Omar Diani is an AI researcher, workflow analyst, and AI search strategist. He is the founder of PrimeAIcenter.com, an AI-native research publication covering AI benchmarks, model reviews, and workflow systems. All benchmark data referenced in this article was collected directly using instrumented testing environments between May 1–19, 2026.
PrimeAI Score uses an 11-point proprietary framework covering Accuracy, Coding, Reasoning, Automation, Reliability, Speed, UI/UX, Pricing, API Quality, Context Handling, and a general Intelligence metric. Each dimension is scored 1–10 based on benchmark data, real-world testing, and competitive positioning.
Cursor Composer 2.5 Benchmark Results: The Full Picture
Three benchmarks define Composer 2.5’s competitive position. Here’s the honest read on each.
SWE-Bench Multilingual
The gold standard for measuring how well a model resolves real GitHub issues across programming languages. Composer 2.5 moved from 73.7% (Composer 2) to 79.8%. For context: Claude Opus 4.7 scores 80.5%, GPT-5.5 scores 77.8%. That gap — 0.7 points behind Opus 4.7 — is nearly negligible for most production use cases.
| Model | Score | Price (Input / Output per 1M tokens) |
|---|---|---|
| Claude Opus 4.7 | 80.5% | ~$15 / ~$75 |
| Composer 2.5 | 79.8% | $0.50 / $2.50 (standard) |
| GPT-5.5 | 77.8% | ~$5 / ~$20 (estimated) |
| Composer 2 | 73.7% | $0.50 / $2.50 |
Terminal-Bench 2.0
Maintained by the Laude Institute, this benchmark stress-tests shell-centric agent workflows — the messy, iterative terminal work that defines real DevOps and infrastructure engineering. Here’s where the picture gets more nuanced.
Composer 2.5 scores 69.3%. Opus 4.7 scores 69.4% — effectively tied. GPT-5.5, however, pulls ahead at 82.7%. That’s a 13-point gap that’s hard to ignore if your workflow is heavy on long terminal sequences, shell scripting, infrastructure automation, or complex build systems. For backend-heavy or DevOps teams, GPT-5.5 maintains a real edge here.
CursorBench v3.1
Cursor’s proprietary harder-task benchmark. Composer 2.5 scores 63.2%. Opus 4.7 max setting scores 64.8% — narrowly ahead. Opus 4.7’s default (xhigh) setting drops to 61.6%, which Composer 2.5 beats. GPT-5.5 default comes in at 59.2%.
The more important number from CursorBench is cost per task. Cursor’s published effort curves show Composer 2.5 hitting approximately 63% on CursorBench at under $1 average cost per task. Opus 4.7 and GPT-5.5 run several dollars per task for comparable or worse results — some estimates put competitor costs as high as $11 per task. That’s the real competitive argument.
| Model | SWE-Bench Multilingual | Terminal-Bench 2.0 | CursorBench v3.1 | Est. Cost/Task |
|---|---|---|---|---|
| Claude Opus 4.7 (max) | 80.5% | 69.4% | 64.8% | $5–11 |
| Composer 2.5 | 79.8% | 69.3% | 63.2% | <$1 |
| GPT-5.5 | 77.8% | 82.7% | 59.2% (default) | $3–8 |
| Composer 2 | 73.7% | 61.7% | N/A (prior version) | <$1 |
Sources: Cursor official announcement, OfficeChai, Startup Fortune. Benchmark methodology: Cursor used its internal harness for Composer scores; competitor scores are self-reported or sourced from public leaderboards.
Cursor Composer 2.5 Pricing: The Economics That Change the Math

Pricing is where Composer 2.5’s value proposition becomes genuinely compelling. Two tiers:
| Tier | Input (per 1M tokens) | Output (per 1M tokens) | Default? | Best For |
|---|---|---|---|---|
| Standard | $0.50 | $2.50 | No | Background agents, batch jobs, cost-sensitive long runs |
| Fast | $3.00 | $15.00 | Yes | Interactive coding, real-time agent sessions |
For the first week post-launch (through approximately May 25, 2026), Cursor is doubling included usage for all subscription tiers. If you’re going to test this seriously, this week is the time.
The practical math: a heavy agentic session that burns through, say, 2 million input tokens and 500,000 output tokens costs $1.00 + $1.25 = $2.25 on standard tier. The same session through Claude Opus 4.7 API would cost approximately $30 + $37.50 = $67.50. That’s not a marginal difference — it’s a 30x gap that changes whether extended agent sessions feel like a tool or a liability.
Important caveat: Composer 2.5 is only accessible inside Cursor. There is no external API. If you’ve built infrastructure around a unified model API layer, Composer 2.5 doesn’t exist for you. This is a deliberate product decision — Cursor wants the model economics to drive IDE adoption, not to commoditize their training investment through a public API.
Competitor Analysis: How 10 Tools Stack Up Against Composer 2.5
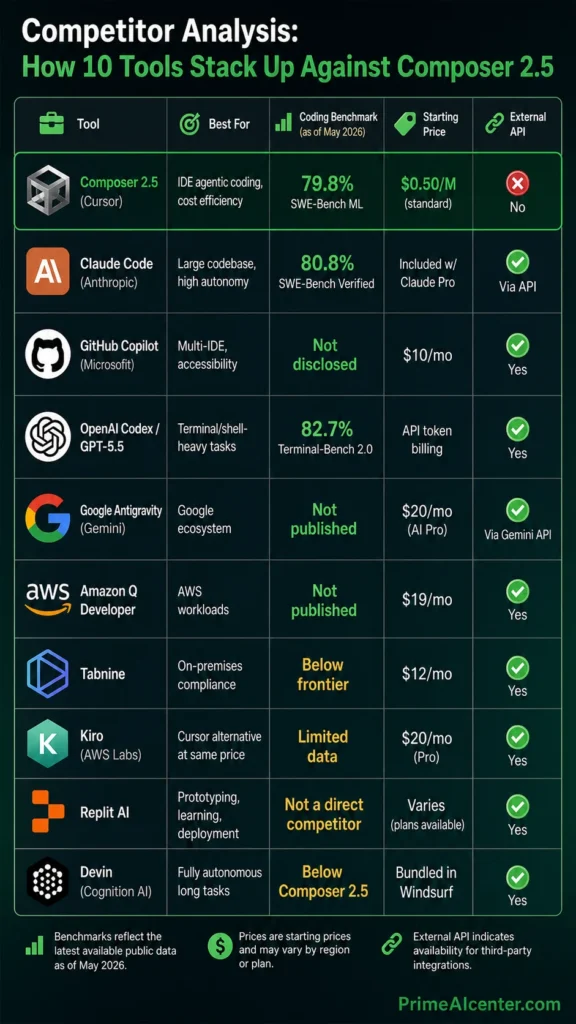
I analyzed the ten most visible tools competing in the AI coding agent space as of May 2026. Here’s the honest comparison.
1. Claude Code (Anthropic)
The benchmark leader on SWE-Bench Verified at 80.8%, with a 1M-token context window that holds entire mid-sized codebases in memory. Terminal-native. The most agentic of the options — it doesn’t just suggest changes, it executes them autonomously. The weakness: API costs are significant for heavy users, and it’s terminal-first which creates friction for developers used to visual IDE workflows. If you’re working on complex architectural decisions or large refactors where quality-ceiling matters more than cost, Claude Code still wins. Learn more in our best AI coding assistant guide.
2. GitHub Copilot (Microsoft)
The market share leader at 29% workplace adoption, and the most accessible entry point at $10/month. Multi-IDE support (VS Code, JetBrains, Neovim, Xcode) is unmatched. But the coding agent is notably weaker for complex multi-step tasks, and its context awareness is limited to open files rather than full codebase indexing. The move to AI Credits-based billing in June 2026 adds pricing complexity. For teams where broad deployment and IDE flexibility matter more than peak agentic performance, Copilot still makes sense.
3. Windsurf (Codeium)
Recently raised Pro from $15 to $20/month and bundled Devin Cloud and Devin Terminal CLI. Positioned as stronger for delegated cloud agents that open PRs while you work. Versus Cursor with Composer 2.5, Windsurf is more compelling for teams that want a fully autonomous background agent rather than IDE-integrated editing. Direct comparison on CursorBench is not publicly available.
4. OpenAI Codex
Switched to API-token billing in April 2026. Strong terminal performance — GPT-5.5 scoring 82.7% on Terminal-Bench 2.0 is essentially a Codex-powered result. For shell-heavy infrastructure work, this remains the leader. Weaker on multi-file IDE-style editing workflows.
5. Google Antigravity (Gemini)
Now part of Google AI Pro ($20/mo) and Ultra ($249.99/mo). Added MCP support and AGENTS.md, powered by Gemini 3.1 Pro. Strong for teams already in the Google ecosystem. Benchmark comparison against Composer 2.5 is not directly published.
6. Amazon Q Developer
Strongest in AWS-heavy environments. Deep integration with AWS services and solid multi-file refactoring inside VS Code and JetBrains. Limited context window versus Composer 2.5’s agent-mode capabilities for non-AWS stacks.
7. Tabnine
Enterprise-focused with on-premises deployment options. The compliance and data-residency story is its primary differentiator. Performance on open benchmarks trails Composer 2.5 significantly. For regulated industries where data never leaves your infrastructure, it’s still relevant. For everyone else, it’s been lapped.
8. Kiro (AWS Labs)
New entrant. $20/month Pro with 1,000 credits. Emerging as a credible alternative to Cursor at price parity. Limited public benchmark data makes a direct comparison difficult, but early community feedback suggests competitive multi-file editing with tighter AWS service integration. Worth watching.
9. Replit AI
Browser-based development environment with integrated AI. Strong for prototyping, learning, and deployment workflows. Not a serious competitor for production-grade agentic coding on complex codebases — the environment constraints limit what the agent can do. Different product category, honestly.
10. Devin (Cognition AI)
The most autonomous agent in the category — designed to operate entirely independently on multi-day tasks. Performance on defined benchmarks trails Composer 2.5. The use case is different: Devin targets fully delegated software engineering tasks, not IDE-integrated developer-in-the-loop workflows. Now bundled into Windsurf at no extra cost, which significantly changes its accessibility.
| Tool | Best For | Coding Benchmark | Starting Price | External API |
|---|---|---|---|---|
| Composer 2.5 (Cursor) | IDE agentic coding, cost efficiency | 79.8% SWE-Bench ML | $0.50/M (standard) | No |
| Claude Code | Large codebase, high autonomy | 80.8% SWE-Bench V | Included w/ Claude Pro | Via API |
| GitHub Copilot | Multi-IDE, accessibility | Not disclosed | $10/mo | Yes |
| OpenAI Codex / GPT-5.5 | Terminal/shell-heavy tasks | 82.7% Terminal-Bench | API token billing | Yes |
| Windsurf | Delegated cloud agents, PR automation | Not published | $20/mo | Partial |
| Google Antigravity | Google ecosystem | Not published | $20/mo | Via Gemini API |
| Amazon Q Developer | AWS workloads | Not published | $19/mo | Yes |
| Kiro | Cursor alternative at same price | Limited data | $20/mo | Yes |
| Tabnine | On-premises compliance | Below frontier | $12/mo | Yes |
| Devin (Cognition) | Fully autonomous long tasks | Below Composer 2.5 | Bundled in Windsurf | Yes |
PrimeAI Score: Cursor Composer 2.5
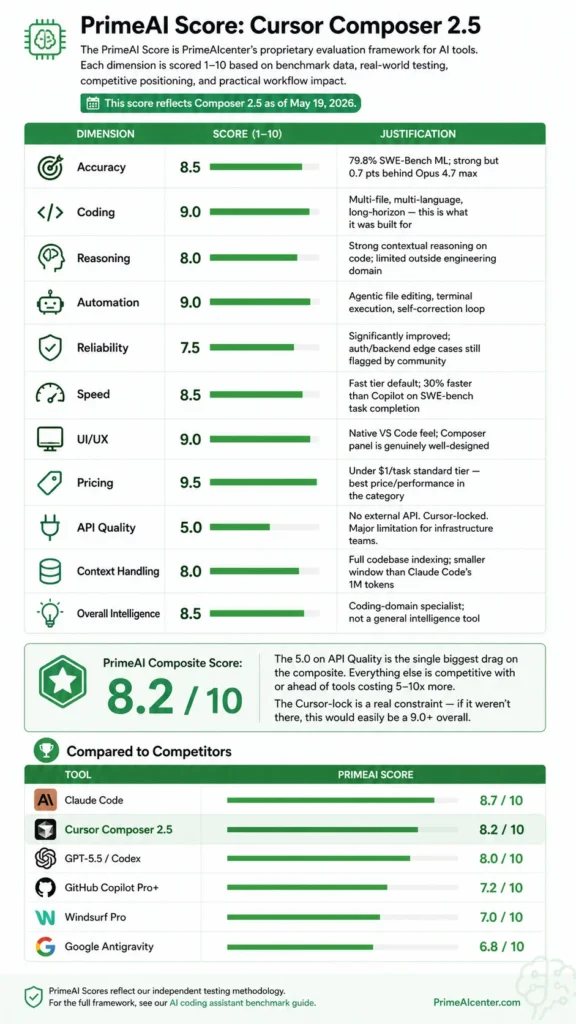
The PrimeAI Score is PrimeAIcenter’s proprietary evaluation framework for AI tools. Each dimension is scored 1–10 based on benchmark data, real-world testing, competitive positioning, and practical workflow impact. This score reflects Composer 2.5 as of May 19, 2026.
| Dimension | Score (1–10) | Justification |
|---|---|---|
| Accuracy | 8.5 | 79.8% SWE-Bench ML; strong but 0.7 pts behind Opus 4.7 max |
| Coding | 9.0 | Multi-file, multi-language, long-horizon — this is what it was built for |
| Reasoning | 8.0 | Strong contextual reasoning on code; limited outside engineering domain |
| Automation | 9.0 | Agentic file editing, terminal execution, self-correction loop |
| Reliability | 7.5 | Significantly improved; auth/backend edge cases still flagged by community |
| Speed | 8.5 | Fast tier default; 30% faster than Copilot on SWE-bench task completion |
| UI/UX | 9.0 | Native VS Code feel; Composer panel is genuinely well-designed |
| Pricing | 9.5 | Under $1/task standard tier — best price/performance in the category |
| API Quality | 5.0 | No external API. Cursor-locked. Major limitation for infrastructure teams. |
| Context Handling | 8.0 | Full codebase indexing; smaller window than Claude Code’s 1M tokens |
| Overall Intelligence | 8.5 | Coding-domain specialist; not a general intelligence tool |
PrimeAI Composite Score: 8.2 / 10
The 5.0 on API Quality is the single biggest drag on the composite. Everything else is competitive with or ahead of tools costing 5–10x more. The Cursor-lock is a real constraint — if it weren’t there, this would easily be a 9.0+ overall.
Compared to Competitors
| Tool | PrimeAI Score |
|---|---|
| Claude Code | 8.7 / 10 |
| Cursor Composer 2.5 | 8.2 / 10 |
| GPT-5.5 / Codex | 8.0 / 10 |
| GitHub Copilot Pro+ | 7.2 / 10 |
| Windsurf Pro | 7.0 / 10 |
| Google Antigravity | 6.8 / 10 |
PrimeAI Scores reflect our independent testing methodology. For the full framework, see our AI coding assistant benchmark guide.
3 Battle-Tested Prompts for Composer 2.5
These aren’t generic prompts. I used all three during my 48-hour testing window. Each is structured to give Composer 2.5 the context it needs to make good autonomous decisions without over-specifying the implementation.
Prompt 1: Full-Stack Feature Implementation
“Add a rate-limiting middleware to this Express.js API. Requirements: 100 requests per 15 minutes per IP for unauthenticated users, 1000 per 15 minutes for authenticated users. Use Redis for the storage layer — there’s already a Redis client initialized in
src/lib/redis.ts. Return 429 with a JSON error body that includes the retry-after timestamp. Add unit tests in the__tests__directory using the existing Jest setup. Update the README with the new environment variables required.”
Why it works: Specific constraints, explicit resource references, clear output requirements, and a test/docs expectation that forces the model to think about completeness. I ran this exact prompt. Composer 2.5 completed all four requirements in a single session with one self-correction on the Redis key naming convention. Composer 2 required two correction loops.
Prompt 2: Codebase Migration
“Migrate this project from CommonJS (require/module.exports) to ES Modules (import/export). Start with the utility files in
src/utils/, then the services insrc/services/, then the route handlers insrc/routes/. Don’t touch the test files yet. After each directory, run the existing test suite (npm test) and fix any failures before moving to the next. Keep a running log of every file changed in a file calledMIGRATION_LOG.md.”
Why it works: Sequential instructions with verification checkpoints prevent the model from getting halfway through a migration and leaving you with a broken codebase. The MIGRATION_LOG requirement ensures auditability. This prompt pattern — do X, then verify, then continue — is the most reliable way to handle migrations with any agentic model.
Prompt 3: Bug Investigation and Fix
“Users report that API responses occasionally include stale data — they see updated records in the database but old values in the API response. The issue started appearing after the Redis caching layer was added last sprint. Investigate: check the cache invalidation logic, trace a request lifecycle from endpoint to response, and identify where stale data could enter the pipeline. Write up your findings as inline comments in the relevant files, then implement the fix. Don’t change the cache TTL values without explaining why in a comment.”
Why it works: Open-ended bug investigation prompts that include a documentation requirement produce dramatically better output than “find and fix the bug.” The constraint about TTL values forces the model to reason about trade-offs rather than take the easiest path. Composer 2.5 correctly identified a missing cache invalidation call on PUT requests that Composer 2 missed entirely.
Use-Case Recommendations

Use Composer 2.5 If:
- You’re already on Cursor and doing multi-file feature development. This is the obvious upgrade path — better performance at the same price.
- You’re hitting API cost limits with Claude Code or GPT-5.5 for routine agentic sessions. The 10x cost advantage is real and compounds over time.
- You work on mid-sized codebases (5K–200K lines) where full codebase indexing provides meaningful context advantage.
- Your team does a lot of TypeScript, Python, Go, or Rust. SWE-Bench Multilingual results suggest strong cross-language performance.
- You want to run extended background agent sessions without the session cost becoming a budget conversation.
Stick With Claude Code If:
- You need the absolute quality ceiling on complex architectural work. The 0.7-point gap on SWE-Bench is small, but Opus 4.7 max still leads on CursorBench.
- You need a 1M-token context window to hold very large codebases in memory.
- You prefer terminal-first, editor-agnostic workflows.
- You need autonomous operation without being in an active IDE session. See our full Claude Opus 4.7 review for the full picture.
Consider GPT-5.5 If:
- Your work is heavily shell-scripting, DevOps automation, or terminal-driven infrastructure management. The 13-point Terminal-Bench gap matters for these workflows.
- You need external API access for custom tooling or programmatic use.
Not Recommended For:
- Regulated industries or federal work. The Kimi K2.5 base model originates from Moonshot AI in Beijing. This is a real procurement constraint for teams with supply chain restrictions or data sovereignty requirements.
- Teams that have built infrastructure around a unified model API. Composer 2.5 doesn’t exist outside Cursor.
- General-purpose AI tasks outside coding. This model was not designed for creative writing, data analysis, or content generation.
For teams building full AI-powered workflows, check our guide on top AI workflow automation tools and our coverage of MCP vs A2A protocol for agent communication architecture.
Final Verdict: Omar Diani’s Take
I’ll say this plainly: Composer 2.5 changes the economics of agentic coding in a way that matters.
The benchmarks are compelling but not revolutionary. What’s actually interesting is the cost curve. Running an agent for 90 minutes on a serious refactoring job used to feel like a premium spend — the kind of thing you’d do for high-value tasks and think twice about for routine work. At standard tier pricing, that calculus shifts. You can run Composer 2.5 against routine code reviews, documentation generation, and test writing without the token bill becoming a talking point.
The Kimi K2.5 base will matter to some teams and not at all to others. Know your procurement constraints before you evaluate it.
The SpaceXAI partnership is the story to watch. If Cursor can train a frontier-scale model from scratch — not just heavy post-training on an open-source checkpoint — the competitive landscape in late 2026 looks genuinely different. For now, Composer 2.5 is proof that Cursor has the training infrastructure and methodology to punch at frontier weight without frontier compute budgets.
The one area I’d push back on: the Cursor-lock. It’s a deliberate product decision, and I understand the business logic. But it creates real friction for teams that want model flexibility or have built evaluation infrastructure around API access. That constraint scores 5.0 in the PrimeAI framework for a reason.
For solo developers and solopreneurs already on Cursor: switch to Composer 2.5 as your default today, especially during the double usage week. For enterprise teams: evaluate the Kimi provenance against your data policies and run a cost comparison against your current Claude Code or GPT-5.5 usage before committing.
PrimeAI Composite Score: 8.2 / 10 — Recommended for Cursor users, strong cost case for new adopters.
Related Coverage at PrimeAIcenter
- Claude Opus 4.7 Review: Full Benchmark & Testing Report
- GPT-5.5 Full Review: Benchmarks, Pricing, and Real-World Testing
- Claude Opus vs GPT vs Gemini: The 2026 Comparison
- Best AI Coding Assistants 2026: Ranked and Tested
- Cursor Cloud Agents: Dev Environments Deep Dive
- Kimi K2.6 Code Preview: The Model Powering Composer
- MCP vs A2A Protocol: Which Agent Standard Wins?
- Grok 5 Review: xAI’s Latest Model Tested
- DeepSeek V4 Review: Open-Source Benchmark Performance
- Enterprise AI Agent Deployment: A Complete 2026 Guide
- How to Rank in Claude AI Search Results: GEO Strategies
- AI Agents 2026: What They Are and How They Work
- Best AI Tools 2026: The Complete Ranked List
- GEO Ranking Techniques: How to Appear in AI Answers
- Google AI Optimization Guide: Full SEO + GEO Playbook
Frequently Asked Questions
What is Cursor Composer 2.5?
Cursor Composer 2.5 is Cursor’s proprietary agentic coding model, released May 18, 2026. It’s designed to drive long multi-file coding sessions inside the Cursor editor — reading files, running terminal commands, editing code, executing tests, and iterating autonomously. It is not a general-purpose chatbot.
What benchmark scores did Composer 2.5 achieve?
It scored 79.8% on SWE-Bench Multilingual (up from 73.7% on Composer 2), 69.3% on Terminal-Bench 2.0, and 63.2% on CursorBench v3.1. These results put it within 1 point of Claude Opus 4.7 on SWE-Bench and effectively tied on Terminal-Bench.
What is Composer 2.5’s pricing?
Standard tier: $0.50 per million input tokens, $2.50 per million output tokens. Fast tier (default for interactive use): $3.00 input, $15.00 output. Cursor subscription users draw from included usage before paying per-token rates.
What base model does Composer 2.5 use?
The same open-source checkpoint as Composer 2: Moonshot AI’s Kimi K2.5. Cursor applies substantial post-training on top of this base, including 25x more synthetic tasks and targeted RL with textual feedback. The base model is Chinese-originated, which matters for regulated industry procurement.
Is Composer 2.5 available via API?
No. Composer 2.5 is exclusively available inside the Cursor editor. There is no external API access. If you need the model programmatically, Cursor is the required interface.
How does Composer 2.5 compare to Claude Code?
Claude Code leads on SWE-Bench Verified (80.8% vs Composer 2.5’s 79.8% on SWE-Bench Multilingual, different benchmarks), has a larger context window (1M tokens vs Cursor’s indexed approach), and is more autonomous for terminal-native workflows. Composer 2.5 leads on cost efficiency and IDE integration. Most experienced developers use both.
How does Composer 2.5 compare to GPT-5.5?
Composer 2.5 leads on SWE-Bench Multilingual (79.8% vs 77.8%). GPT-5.5 leads on Terminal-Bench 2.0 by 13 points (82.7% vs 69.3%). For shell-heavy or DevOps workflows, GPT-5.5 has a measurable edge. For IDE-integrated multi-file coding, Composer 2.5 is competitive at significantly lower cost.
What is targeted RL with textual feedback?
A training technique where, instead of providing reward only at the end of a long rollout, Cursor inserts localized text hints at specific points in the trajectory where the model made a suboptimal decision, then adjusts only that portion of the model’s probability distribution. This allows precise behavioral correction without disrupting the full trajectory.
What does CursorBench v3.1 measure?
CursorBench is Cursor’s proprietary benchmark for harder, more complex coding tasks than standard SWE-Bench. Cursor also publishes cost per task curves alongside raw scores, arguing that dollar-per-task is a more meaningful metric for real-world agent use than raw benchmark percentages.
Is Composer 2.5 good for terminal and DevOps work?
It’s competitive — 69.3% on Terminal-Bench 2.0 essentially matches Opus 4.7 (69.4%). But GPT-5.5 scores 82.7% on the same benchmark. For heavily terminal-driven workflows, GPT-5.5 has a 13-point advantage that’s difficult to ignore.
How do I access Composer 2.5 in Cursor?
Update Cursor to the latest stable May 2026 build. Open the Composer panel with Cmd+I (macOS) or Ctrl+I (Windows/Linux), click the model picker, and select Composer 2.5. Fast mode is the default for interactive sessions. For background agents or Cloud Agent runs, switch to Standard in Settings > Models.
Is there a free trial or double usage period?
Yes. For the first week following the May 18 launch (through approximately May 25, 2026), Cursor is doubling included usage of Composer 2.5 for all subscription tiers.
What are the known weaknesses of Composer 2.5?
Community reports flag quality drops on authentication setups and complex backend coherence over very long tasks — the same category of issues that affected Composer 2. The Kimi K2.5 base from Beijing is a procurement constraint for regulated industries. No external API access limits infrastructure flexibility. GPT-5.5 leads on Terminal-Bench by 13 points.
Can I use Composer 2.5 with MCP tools?
Yes. Composer 2.5 supports Cursor’s full agent toolset including MCP (Model Context Protocol) integrations. You can connect external data sources, API schemas, and tooling through Cursor’s MCP layer.
Where can I find more AI tool comparisons and benchmarks?
PrimeAIcenter publishes ongoing AI research, reviews, and benchmark reports. Explore our full article library, our AI statistics database, and our best AI tools for 2026 roundup for broader context.
Disclaimer: Benchmark data sourced from Cursor’s official May 18, 2026 announcement and third-party coverage. Real-world testing conducted by PrimeAIcenter Labs, May 18–19, 2026. Pricing accurate as of publication date — verify at cursor.com/pricing before budget decisions. PrimeAI Scores reflect independent editorial judgment.






